一 简介
java中接触到"池"这个概念的地方有不少。最开始是常量池、数据库连接池、线程池... 对于某些发散思维很强或者善于举例的人来说,可能会想方设法将java的某些概念和生活中的某些事物进行比拟,好加深理解。惭愧的是,关于生活中的"池",我最先想到的是水池、化粪池(我是农村银)... ...
再后来,有了一些经验之后。才慢慢体会到。编程语言中的"池",侧重强调的不是作为容器的存储功能,而是容器中的元素能够重复利用的功能。
java中有线程池的概念,jdk也有相应的实现类。本文并非探讨JDK源码,大失所望者请勿浪费时间往下看。我一向不喜欢看别人的代码。不是狂妄。而是不希望自己的想法被别人的思路绑架。至少要等我自己的代码出现了很大的问题,严重碰壁的时候,才去学习借鉴别人的想法。
1 为什么要使用线程池呢?
答:线程池可以提高程序的性能。
2 使用了多线程本身不就是可以提高性能了吗?为什么线程池可以提高性能?
答前半个问题:多线程不一定提高性能,甚至反而降低了性能。多线程环境中,如果每个线程run方法中运行的代码耗时比较少,少于创建、启动该线程所消耗的时间。使用多线程就是一种浪费。
场景一 :创建线程、开启线程、线程开始执行这段耗时 远远大于 线程的运行时间。
单线程搜索文件和多线程搜索文件性能对比:
单线程:
/** * 单线程搜索文件。 * @author Administrator * */public class SingleThreadSearchFile { public static void main(String[] args) { long t1 = System.currentTimeMillis(); //在 G:\\代码库备份 这个目录中搜索包含"笔记"的文件夹或文件。并打印出来。 searchFile(new File("G:\\代码库备份"), "笔记"); long t2 = System.currentTimeMillis(); System.out.println("耗时:"+(t2-t1)+"ms"); } public static void searchFile(File file,String keyword){ if(file.isDirectory()){ File []files = file.listFiles(); if(files!=null){ isKeyWordContained(file, keyword);//搜索业务。 for(File f : files){ searchFile(f, keyword); } } }else{ isKeyWordContained(file, keyword);//搜索业务。 } } public static void isKeyWordContained(File file,String keyword){ int index = file.getName().indexOf(keyword); if(index !=-1){ System.out.println(file.getAbsolutePath()); } }} 多线程:
/** * * @author Administrator * */public class MultiThreadSearchFile { public static void main(String[] args) throws InterruptedException { long t1 = System.currentTimeMillis(); //在G:\\代码库备份 这个目录中搜索包含"笔记"的文件夹或文件。并打印出来。 searchFile(new File("G:\\代码库备份"), "笔记"); long t2 = System.currentTimeMillis(); System.out.println("耗时:"+(t2-t1)+"ms"); } public static void searchFile(File file,String keyword){ if(file.isDirectory()){ File []files = file.listFiles(); if(files!=null){ isKeyWordContained(file, keyword); //取出目录名,判断是否包含关键字。 for(File f : files){ searchFile(f, keyword); } } }else{//是否文件。 isKeyWordContained(file, keyword); } } //被调用一次,则开一个线程来查找。所谓的查找其实仅仅是获取文件名,与关键字进行简单的比对。 public static void isKeyWordContained(File file,String keyword){ Thread t = new Thread(){ public void run(){ int index = file.getName().indexOf(keyword); if(index !=-1){ System.out.println(getName()+" "+file.getAbsolutePath()); } } }; t.start(); try { t.join(); }catch (InterruptedException e) { } }} 对比结果:相同的目录查找相同的结果。单线程60ms多线程220--400ms变动。单线程完胜。原因很简单:我们虽然使用了多线程,但是多线程里面要做的事情仅仅是几行简单的不耗时的代码。多线程同运行run方法带来的优势已经被创建线程、开启线程所需要的时间给抵消掉了。
场景二 创建线程、开启线程、线程开始执行这段耗时 远远 小于 线程的运行时间
多线程的应用场景在于,执行那些需要耗时的操作。例如,使用多线程 + Socket实现的Http服务器。每个连接都开启一个线程来处理请求响应。由于存在网络延时。因此多线程的优势体现出来。
再如,将上面的案例需求修改如下:搜索某个文件夹中,文件内容 包含指定关键字的.txt, .java , .js文件。
单线程的业务代码改为:
public static void isKeyWordContained(File file,String keyword){ if(file.getName().endsWith(".java") || file.getName().endsWith(".txt")|| file.getName().endsWith(".js")){ //创建流对文件内容进行读取,并且判断。 } } 多线程业务代码改为:
public static void isKeyWordContained(File file,String keyword){ Thread t = new Thread(){ public void run(){ if(file.getName().endsWith(".java") || file.getName().endsWith(".txt")|| file.getName().endsWith(".js")){ //创建流对文件内容进行读取,并且判断。 } } }; t.start(); try { t.join(); }catch (InterruptedException e) { } } 由于使用IO读取文件是个相对耗时的操作,此时多线程的优势展示出来了。
答后半个问题:经过上述分析,已经得出了个结论。如果不使用线程池,由于创建线程、开启线程过程中,JVM要为每个线程分配内存空间,相对耗时,所以不一定提高性能。如果能将线程放入一个池里,不需要每次都开启和运行。就在一定程度上提高性能。
二 想法
如果实现线程池?回想线程池的作用:
①首先得是个容器,容器里面装有线程。可以是Thread[]或者List<Thread>
②其次容器中的线程还得重复利用,意味着线程不死,如何不死?最粗暴的方法是run方法中死循环(一定条件下可调出)
矛盾:那如何让线程执行自定义的代码,自定义的代码放在哪里?
答案是:任务。
这里引出任务的概念,这里的任务,是我们自定义个一个接口。
public interface MyTask { //被调用。被线程池中的线程调用。 public void execute()throws Exception;} 我们的代码放在哪里呢?就放在子类的execute方法里。
即,我们创建一个实现类,把代码放在execute方法中。然后创建该类的对象,一个类就表示一个任务。
好啦,到这里,整理一下我们线程池的所有流程:
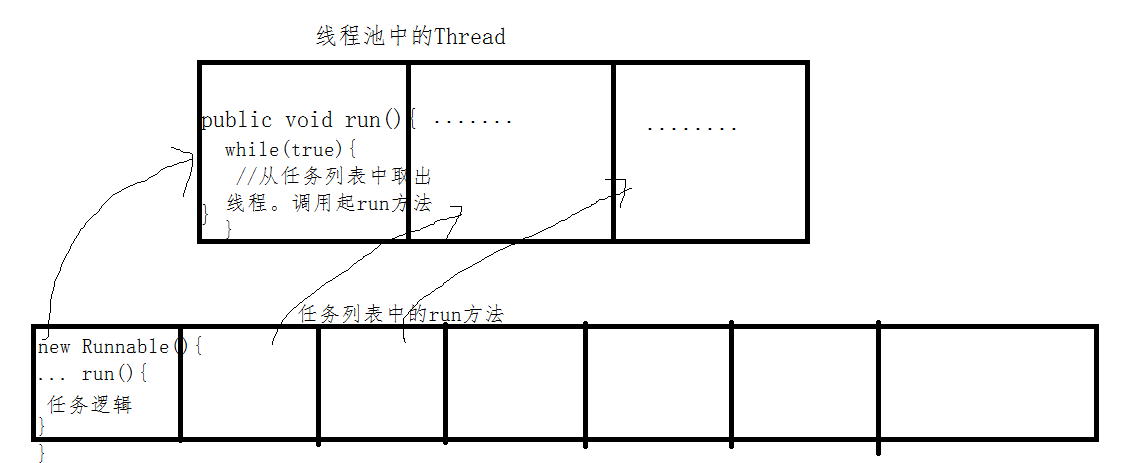
应该要有一个线程池管理类,里面包含着任务列表,MyTask[]或者List<MyTask>,也可以用阻塞队列。
也包含了线程列表。并且线程可以运行状态。
使用线程池时,只需要创建任务对象,把代码写好,把对象丢进线程池。
理想的编程方式如下:
//创建线程池。//创建任务1 ,并加入线程池。//创建任务2,并加入线程池//创建任务3,并加入线程池... 伪代码如下: //1 创建线程池。指定池里有5个正在运行的线程(活跃) MyThreadPools pools = new MyThreadPools(5); //2 创建任务列表。并加入线程池。 Random r = new Random(); for(int i=0;i<20;i++){ MyTask t = new MyTask() { @Override public void execute() throws Exception{ System.out.println("产生随机数:"+r.nextInt()); } }; pools.submit(t); } 三 代码
完整代码,2个类和一个接口。
MyTask.java代码如下
public interface MyTask { //被调用。被线程池中的线程调用。 public void execute()throws Exception;} MyThreadPools.java代码如下
/** * 线程池。管理类。 * @author Administrator * */public class MyThreadPools { //实际应用中,可将以下两个换成阻塞队列。这样就避免在run方法中手动使用synchronized关键字来同步。 private List threadList = new ArrayList ();//线程池的线程列表。 private List mytasklist = new LinkedList ();//任务列表。 //num表示线程池中线程的总数。 public MyThreadPools(int num){ for(int i=0;i 0)task = mytasklist.remove(0); else break;//一定条件下推出。也可以不退出。 } if(task!=null ){ System.out.println(getName()+"线程执行任务"); try { task.execute(); } catch (Exception e) { System.out.println("有任务有异常。执行失败。"); } System.out.println(getName()+"线程执行完毕"); } } System.out.println("线程"+getName()+"退出"); } }} TestMain.java代码如下
public class TestMain { public static void main(String[] args) { //1 创建线程池。 MyThreadPools pools = new MyThreadPools(5); //2 创建任务列表。并加入线程池。 Random r = new Random(); for(int i=0;i<20;i++){ MyTask t = new MyTask() { @Override public void execute() throws Exception{ System.out.println("产生随机数:"+r.nextInt()); } }; pools.submit(t); } }} 四 优化
这就完了吗?肯定不会。我们这里的线程池,仅仅实现的是固定数目的线程池,并且线程没事干的时候就退出,这个机制有待商榷。更多的时候,我们需要根据任务的数量来决定线程中最小活跃的线程数量、最大线程数量等。因此还可以做得更加完善。但至少以上已经实现了线程池的根本模型。相信再开发自己的线程池,也就不是难事了。
有一点要说明:JDK提供的线程池,并没有新定义一个类来表示任务。它使用了Runnable接口作为任务。因此,我们的自定义逻辑就写在run方法中。线程池中的线程会调用任务的run方法。